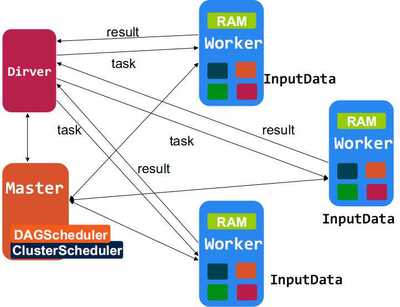
Spark是一个开源的分布式计算系统,由加州大学伯克利分校的AMPLab开发,现已成为Apache软件基金会的顶级项目。它以其高效的内存计算能力和易用的API而闻名,广泛用于大数据处理和机器学习等领域。
在数据库领域,Spark通过其核心组件Spark SQL提供了强大的数据处理能力。Spark SQL支持结构化数据的查询,可以无缝集成Hive、Avro、Parquet等数据源,并通过DataFrame和Dataset API进行高效的数据操作。与传统的MapReduce相比,Spark的内存计算特性显著减少了磁盘I/O,提升了处理速度,尤其适用于复杂查询和实时分析。Spark还支持流处理(Spark Streaming)和图计算(GraphX),使其在数据库系统中能够处理多样化的数据工作负载。
在软件工程方面,Spark的应用主要体现在大数据项目的开发与维护中。软件工程师可以利用Spark的Scala、Java、Python或R语言API快速构建分布式应用。例如,在火龙果软件工程等企业中,Spark常用于构建数据管道、实现ETL(提取、转换、加载)流程,以及开发机器学习模型。其统一的编程模型简化了代码编写,同时Spark的容错机制和资源管理功能(如与YARN或Mesos集成)提高了系统的可靠性,有助于软件团队遵循敏捷开发原则,快速迭代和部署应用。
Spark不仅是一个高效的分布式计算系统,还在数据库和软件工程领域发挥着关键作用。通过优化数据处理流程和提升开发效率,它帮助企业如火龙果软件工程更好地应对大数据挑战,推动技术创新。